이번 시간의 목차
1. 인간의 뇌를 흉내내기 위한 길
2. 잠깐! 이제는 구글 코래버러토리를 이용해 보자!
3. 머신&딥러닝을 위한 플랫폼, 텐서플로우
4. 딥러닝: 인공 신경망을 구축해 보자!
5. 데이터를 드라이브에서 가져오자!
6. 이미지를 모델에게 인식시켜 보자!
7. 인공지능: 딥러닝이 무엇일까?
8. 학습된 모델은 나중에도 쓸 수 있다!
9. 마무리
자, 가자! 파이썬의 세계로!
인간의 뇌를 흉내내기 위한 길
인간의 뇌는 뉴런이라는 수없이 많은 신경세포가 다른 신경세포와 연결되어 있고, 서로 화학적 신호를 주고받는 과정을 통해 고등한 사고를 한다. 이러한 신경세포와 그 연결구조를 완벽하게 재현할 수 있다면 인간의 뇌와 유사한 인공뇌(Artificial Brain)을 만들 수 있겠지만, 현재의 기술로는 구현이 어렵다.

하지만 뉴런을 대신하는 인위적인 함수와 신경전달물질을 대신하는 숫자값을 다른 함수의 입력으로 넘겨주는 프로그램은 구현할 수 있다. 이렇게 인공적인 신경세포(Artificial Neuron)를 흉내내는 프로그램을 퍼셉트론(Perceptron)이라 한다.

퍼셉트론이 하나의 신경세포를 흉내내는 것이라면 인간의 뇌는 위처럼 입력신호를 바로 출력으로 바꾸는 것이 아니라 숨겨진 층을 거친 뒤에 출력 신호를 내놓는 것이다. 이를 좀 더 복잡하게 만들면 많은 층을 거쳐가는 깊은 신경망이 될 것이다. 이렇게 복잡한 구조를 가지면 더 복잡한 일도 수행할 수 있을 것이다... 라는 것이 딥러닝(Deap Learning) 개념의 시작이다.

단순한 형태의 인공 신경망은 위처럼 표현할 수 있다. 두 개의 입력 노드가 하나의 출력 노드에 연결된 인공 신경망을 보이고 있다. 입력 데이터가 입력 노드에 전달되면 신경망 연결을 통해 신호가 전달되고, 그 과정에서 연결 강도가 곱해져서 출력 노드로 넘어간다. 출력 노드는 전달된 신호를 모두 합하거나 신호를 다음에 보낼 때 얼마나 강하게 보낼지를 결정하는 두 가지 기능을 한다. 이때 합산된 신호를 다음 계층으로 보낼지 말지는 활성화(Activation) 함수에 의해 결정된다. 지금 출력 노드가 최종 노드라고 하면 이 결과가 옳은지 답이 되는 레이블과 비교해서 오차를 구한다.

하지만 실제 생물의 신경 세포는 모아진 신호가 일정 수준을 넘어야 다음으로 신호를 보낼 수 있다. 이런 동작을 흉내낼 수 있는 가장 단순한 방법은 위 그림의 두 번째 같은 계단함수가 될 것인데... 이 함수는 미분이 되지 않는 지점이 있어서 최적화하기는 좀 어렵다.
그래서 전통적으로 많이 사용되던 함수가 시그모이드(Sigmoid) 함수였다. 그런데 이 활성화 함수로는 깊은 층을 가진 신경망을 학습시키기 어렵다. 이후 다양한 활성화 함수가 사용되었는데, 요즘은 ReLU라고 불리는 정류 선형 유닛(Recitified Linear Unit) 함수가 좋은 결과를 내는 것으로 알려져 있다. 출력이 여러 개가 있을 때에 출력을 비교해서 출력 노드의 합이 1이 되도록 하는 활성화 함수는 소프트맥스(Softmax)라는 것도 있다. 이것은 분류 문제의 최종 출력단에 적합하다.
신경망은 연결강도를 조정해서 동작을 변경한다. 따라서 인공 신경망의 학습이라 하면 출력을 목표치와 비교하여 오차를 계산하고 이 오차를 줄이는 방향으로 연결강도를 변경하는 일이 된다. 이 연결강도를 파라미터(Parameter)라 한다.
오차를 줄이는 방법에는 지난 시간에서 살펴본 최소제곱오차 등을 이용할 수 있다. 이렇게 오차를 줄이는 일은 최적화(Optimization)라 부르는데, 이것이 바로 학습이다. 그리고 이러한 파라미터를 찾기 위한 학습 과정을 조절하는 변수들을 하이퍼파라미터(Hyperparameter)라고 한다.
잠깐! 이제는 구글 코래버러토리를 이용해 보자!
지금까지 우리는 파이썬에서 제공하는 IDLE Shell에서 작업을 해봤지만, 이 말고도 파이썬을 다룰 수 있는 플랫폼이 존재한다. 바로 구글 코래버러토리이다. 구글 코래버러토리(Google Colaboratory, 구글 코랩이라고도 한다.)는 웹 환경에서 대화식으로 프로그램을 작성&실행할 수 있는 오픈 소스 프로젝트인 주피터 노트북 기반의 파이썬 개발을 위한 환경을 제공한다. 또한 클라우드 환경에 코드가 저장되기 때문에 공유나 협업이 쉽다.
이 코랩 서비스의 장점을 설명하자면 아래와 같다.
- 파이썬을 설치하지 않아도 웹 브라우저를 이용하여 주피터 노트북에서 파이썬을 사용할 수 있다.
- 클라우드 환경이므로 다른 사용자들과 파일 공유가 가능하고, 협업을 통한 개발도 쉽게 할 수 있다.
- 넘파이, 판다스, 사이킷런, 텐서플로우, 파이토치 등과 같은 데이터 분석 및 머신러닝 패키지들이 설치되어 있어서 개별적으로 설치할 필요가 없다.
- 클라우드에서 제공하는 GPU(Graphics Processing Unit그래픽스 처리 장치)와 TPU(Tensor Processing Unit, 텐서 처리 장치)를 사용할 수 있다.
구글 코랩을 사용하려면 다음 웹 사이트에 접속하여 구글 계정으로 로그인하면 된다.
https://colab.research.google.com/
Google Colaboratory
colab.research.google.com
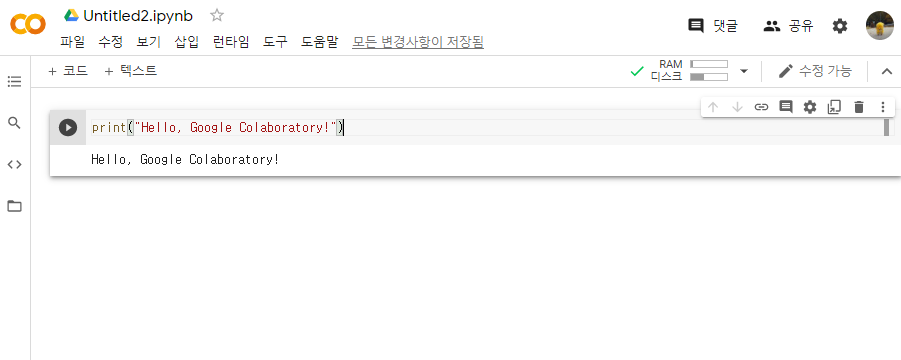
로그인을 하고 새 파이썬 파일 노트를 생성하면 이처럼 셀(Cell)이 하나 뜬다. 이 셀에서 코드를 입력하고 왼쪽의 재생버튼 혹은 키보드 Ctrl+Enter키를 누르면 해당 셀에 있는 코드를 실행할 수 있다. 위의 예시에서는 "Hello, Google Colaboratory!" 라는 문자열을 출력해보았다.
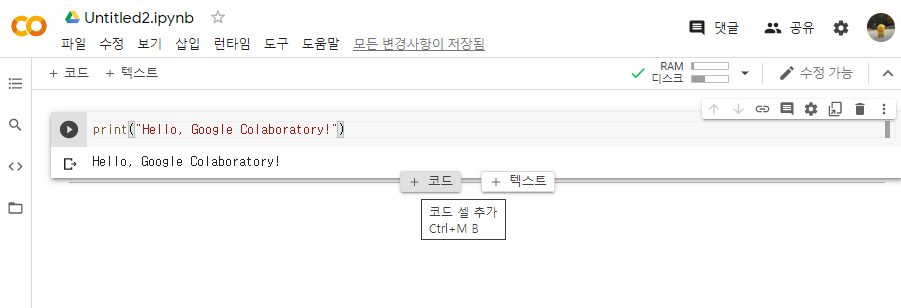
새로운 셀을 생성하고 싶으면 상단 메뉴바의 '삽입 - 코드 셀' 을 이용하거나, 코드 셀의 아래에 마우스 커서를 갖다대어 코드 추가 버튼을 누르면 된다. 텍스트 셀은 코드 내부가 아닌 외부에서 주석을 달기 편하다.
머신&딥러닝을 위한 플랫폼, 텐서플로우
텐서플로우(Tensorflow)는 머신러닝과 딥러닝을 위한 오픈소스 플랫폼으로, 구글의 인공지능 개발부서에서 개발해서 내부적으로 사용하다가 2015년에 오픈소스로 공개되어 현재는 텐서플로우2 버전까지 발전했다.

머신러닝과 딥러닝을 위한 플랫폼은 Tensorflow, Theano, Pytorch, mxnet, keras, scikit-learn, NLTK 등 여러 종류가 있는데, 이 중에서도 가장 많은 사용자를 확보한 플랫폼이 텐서플로우이다. 텐서플로우는 우수한 기능과 서비스를 제공할 뿐만 아니라 병렬처리를 잘 지원하고, 고급 신경망 네트워크 모델을 쉽게 구현할 수 있기 때문에 인기가 많다.
조금 전에 다룬 구글 코랩을 사용하면 별도의 복잡한 설치과정 없이 텐서플로우를 바로 이용할 수 있다. 이번 실습은 셸이 아닌 코랩에서 해 보자!
저번 시간에 살펴본 사이킷런의 경우 붓꽃, 보스턴 집값, 당뇨환자 데이터 등의 예제 데이터를 기본적으로 제공하고 있다. 텐서플로우 역시 사용자를 위한 많은 학습 데이터를 제공하고 있는데, 이 중 하나가 바로 패션 MNIST이다. 패션 MNIST는 운동화나 셔츠같은 옷과 신발의 이미지와 이 이미지에 대한 레이블을 제공한다. 이미지의 개수는 6만 장이고, 각 이미지의 사이즈는 28*28px 이다. 이 6만 장 말고도 테스트를 위해 1만 장의 이미지가 따로 또 있다.

|
import tensorflow as tf #텐서플로우를 tf 라는 이름으로 불러옴.
from tensorflow import keras #텐서플로우에서 keras를 불러옴.
import numpy as np
import matplotlib.pyplot as plt
#패션 MNIST 데이터를 kears의 데이터세트에서 불러옴.
fashion_mnist = keras.datasets.fashion_mnist
#학습용/테스트용으로 분리
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
------------
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/tra
32768/29515 [==================================] - 0s 0us/step
...
|
cs |
패션 MNIST 이미지는 텐서플로우 중에서도 케라스(Keras) 모듈에서 제공하고 있다. 위의 코드를 입력하면 케라스에서 패션 MNIST 이미지를 가져와서 학습용/테스트용 데이터로 분리까지 끝난다.
우리가 가져온 데이터를 좀 더 상세하게 살펴보자. 학습 데이터 집합에 있는 데이터 중에서 가장 먼저 나타나는 3개의 이미지를 가져와서 출력하려면 matplotlib을 활용할 수 있다.
|
fig = plt.figure()
ax1 = fig.add_subplot(1, 3, 1)
ax2 = fig.add_subplot(1, 3, 2)
ax3 = fig.add_subplot(1, 3, 3)
ax1.imshow(train_images[0])
ax2.imshow(train_images[1])
ax3.imshow(train_images[2])
plt.show()
|
cs |

이미지 파일 형태인 학습 데이터의 첫 번째 데이터와 두 번째 데이터, 그리고 세 번째 데이터를 가져오니 각각 구두, 티셔츠, 티셔츠임을 확인할 수 있다. 이 이미지들의 레이블을 출력해보면 아래와 같다.
|
print(train_labels[:3])
----
[9 0 0]
|
cs |
각각 9, 0, 0을 나타내는 것을 볼 수 있다. 이 레이블이 의미하는 바는 데이터 내에는 없다. 케라스 홈페이지에 접속해서 데이터셋 중 패션 MNIST 항목에 가면 아래와 같은 표로 설명해주고 있다. 표에 따르면 첫 번째 이미지는 발목 부츠, 두 번째와 세 번째는 티셔츠나 탑에 해당하는 것임을 알 수 있다.

딥러닝: 인공 신경망을 구축해 보자!
이번에는 딥러닝(Deap Learning)에 대해 알아보려 하는데, 딥러닝을 이해하고 활용하기 전에 배경지식을 미리 조금 채워야 한다. 먼저 인공신경망의 기본적인 이해를 바탕으로 딥러닝에 대한 첫 걸음을 시작해 보자.
딥러닝이라는 것은 인공신경망의 층(Layer)을 깊이 쌓아 학습을 하는 것이다.
|
model = keras.Sequential([
keras.layers.Flatten(input_shape = (28, 28)),
keras.layers.Dense(128, activation = 'relu'),
keras.layers.Dense(10, activation = 'softmax')
])
-------
출력 없음
|
cs |
위의 코드를 자세히 설명해보자면 이렇다.
*3개의 층을 가진 네트워크 모델을 생성
- Flatten 계층 : 입력은 (28, 28)
- Dense 네트워크 : 출력 128, 활성화 방법 : ReLU
- Dense 네트워크 : 출력 10, 활성화 방법 : SoftMax
첫 번째 줄은 2차원 입력을 1차원으로 변경하는 Flatten 이고, 그 다음 두 층은 촘촘한 연결을 하는 Dense 네트워크이다. Flatten 네트워크에서는 입력을 그대로 한 줄로 만드는 것이기 때문에 필요한 매개변수는 입력의 크기이다. 이 경우는 패션 MNIST 이미지 크기인 28*28이다. Dense 네트워크의 입력은 앞 층에서 주어지기 때문에 몇 개의 출력으로 연결할지를 정하는 매개변수가 있다. 그리고 그 출력 값을 정하는 함수가 활성화(Activation) 함수이다. 위의 예시의 활성화 방법은 ReLU와 SoftMax이다.

이와 같이 1차원 배열로 변환된 784개의 값은 신경회로망을 통과하여 10개 중 하나의 범주(Category)로 분류된다. 이때 숨어있는 학습층을 만드는 명령이 keras.layers.Dense()이다. Dense()는 학습을 위한 연결을 밀집된(Dense) 구조 혹은 완전 연결(Fully Connected) 층으로 한다는 의미이다.
최종적으로 10개의 카테고리에 입력이 연결되도록 하는 케라스 모델을 keras.Sequential()로 생성했다. 이처럼 텐서플로우와 케라스를 이용하면 위와 같은 복잡한 노드와 그 구조를 손쉽게 생성할 수 있다.
이 모델은 아직 데이터를 가지고 학습한 상태가 아니다. 신경망의 학습은 기본적으로 추측을 한 뒤에 정답과 비교하여 오차가 얼마인지 확인한 뒤에 이 오차를 줄이는 방법으로 연결의 강도를 조절하는 것이다. 이때 오차를 측정하는 방법과 오차를 줄이는 방법을 지정해야 학습이 이루어진다.
|
model.compile(optimizer = 'adam',
loss = 'sparse_categorical_crossentropy',
metrics = ['accuracy'])
|
cs |
모델을 점점 더 좋은 상태로 만드는 것을 최적화라고 한다는 것을 이미 배웠다. 이를 위해서는 현재 모델이 얼마나 잘못되었는지를 알아야 한다. 현재 모델의 정답과 실제 정답의 차이가 오차이고, 이 오차를 측정하는 것이 손실함수이다. 위의 코드에서는 sparse_categorical_crossentropy 함수를 손실함수로 설정했다.
이렇게 모델이 완성되면 학습용 데이터와 정답을 주고 학습을 실시하면 된다. 학습을 시작하는 함수는 fit(x, y) 메소드임을 우리는 이미 알고 있다. 우리는 여기에 한 가지 인자를 추가할 것이다. 에폭(Epoch)이다. 학습용 데이터 모음을 가지고 몇 번 학습하는지를 정한다.
|
model.fit(train_images, train_labels, epochs = 5)
------
Epoch 1/5
1875/1875 [==============================] - 5s 3ms/step - loss: 3.0694 - accuracy: 0.6985
Epoch 2/5
1875/1875 [==============================] - 5s 3ms/step - loss: 0.7092 - accuracy: 0.7494
Epoch 3/5
1875/1875 [==============================] - 5s 3ms/step - loss: 0.6030 - accuracy: 0.7862
Epoch 4/5
1875/1875 [==============================] - 5s 3ms/step - loss: 0.5200 - accuracy: 0.8191
Epoch 5/5
1875/1875 [==============================] - 5s 3ms/step - loss: 0.5080 - accuracy: 0.8252
<tensorflow.python.keras.callbacks.History at 0x7fe8ee270610>
|
cs |
위의 코드에서는 에폭을 5로 지정했으므로 훈련을 5차례 반복한다.
에폭이 진행되면서 매 에폭 단계에서의 손실값 loss와 정확도 accuracy가 화면에 출력된다. 이 값의 변화를 자세하게 살펴보면 loss는 줄고, accuracy는 증가하고 있다.
|
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose = 2)
print('\n테스트 정확도:', test_acc)
----
313/313 - 0s - loss: 0.5940 - accuracy: 0.7995
테스트 정확도: 0.7994999885559082
|
cs |
이제 학습된 모델이 정답 레이블을 잘 맞추는지 테스트 데이터를 넘겨줘 보자. 테스트 데이터의 분류 결과는 훈련용 데이터만 학습한 모델보다 정확도가 조금 떨어질 수도 있다.
이렇게 학습한 모델로 이제 실제로 분류를 시켜보자.
우선 대상이 될만한 데이터를 확보해야 한다. 가장 간단한 것은 이미 가지고 있는 test_images 배열에 있는 이미지를 가져오는 방법이다.
|
test_images.shape
----
(10000, 28, 28)
|
cs |
이 데이터의 형태를 출력해보면 (10000, 28, 28) 로 나타나는데, 이것은 사이즈가 28*28px인 10000개의 이미지를 가진 3차원 배열이라는 뜻이다.

|
import numpy as np
randIdx = np.random.randint(0, 1000)
plt.imshow(test_images[randIdx])
|
cs |
우선 넘파이의 랜덤정수를 이용해서 아무 이미지나 가져와 봤다. (랜덤이라서 위의 이미지와 다른 이미지가 출력될 수도 있다!) 이 데이터를 모델에 집어넣어 결과를 얻는 것은 predict() 함수이다.
|
yhat = model.predict(test_images[randIdx])
---
WARNING:tensorflow:Model was constructed
with shape (None, 28, 28) for input KerasTensor
...
|
cs |
그런데 이 상태에서 predict() 함수를 바로 써 버리면 에러가 발생한다. test_images[randIdx]의 형태는 (28, 28)이고 이것은 28개 1차원 배열을 입력 데이터로 하는 것이며 이 입력 데이터가 28개 제공된 것으로 해석하는 것이다. 즉, 모델에서 사용하는 차원과 이미지의 차원이 일치하지 않는 것이다. 이때는 저번에도 사용했던 넘파이의 newaxis 특성을 사용하면 된다. 이것을 이용하여 이 데이터를 (1, 28, 28) 형태로 만들어주면 될 것이다.
|
yhat = model.predict(test_images[randIdx][np.newaxis, :, :])
print(yhat)
----
[[9.8246759e-01 4.2572534e-08 9.3436147e-06 9.2117181e-05 4.6066359e-10
1.5386454e-13 1.7430846e-02 4.3432301e-28 9.0815551e-09 0.0000000e+00]]
#0번 노드의 출력이 가장 크므로 0번, 티셔츠로 분류함.
|
cs |
이제 제대로 작동한다!
결과를 살펴보니 10개의 노드 중에서 0번 노드의 출력이 9.824... 정도로 가장 큰 것을 볼 수 있다. 따라서 이 이미지는 0번 레이블인 '티셔츠'로 분류할 수 있다.
그런데 우리가 직접 클래스를 찾아서 어느 레이블이 어느 종류를 뜻하는지 알고 확인해서 티셔츠라고 알 수 있는 것이지, 찾아보지 않았으면 몰랐을 것이다. 게다가 모델이 출력하는 최종 결과는 확률 10개를 다 보여주기 때문에 무엇인지 한 눈에 알기가 어렵다. 그러니 이번에는 일치도가 높은 클래스를 찾아 출력해 보자.
|
#argmax()는 배열에서 가장 큰 값을 갖는 '인덱스'를 반환한다.
yhat = np.argmax(model.predict(test_images[randIdx][np.newaxis, :, :]))
yhat
#클래스 이름 리스트
class_names = [ 'T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
#argmax()가 반환한 인덱스에 해당하는 클래스 이름을 출력
print(class_names[yhat])
----
T-shirt/top
|
cs |
어려울 것은 없다. 넘파이의 argmax()를 사용하면 괄호 속에 들어온 배열 속에서 최댓값을 갖는 인덱스를 반환한다. 클래스 이름이 있는 리스트를 만들어서 최댓값 인덱스에 맞는 클래스 이름을 찾아낼 수 있다.
데이터를 드라이브에서 가져오자!
만약 케라스에서 제공되는 패선 MNIST 데이터가 아닌 임의의 데이터를 입력으로 제공하고 싶을 때는 어떻게 해야 할까? 그렇다면 이미지를 읽고 이를 입력의 크기 28*28로 변환하는 일이 필요하다. 이를 위해서는 구글 코랩과 연동하기 좋은 구글 드라이브를 이용해보자. 구글 계정이 있으면 드라이브도 쓸 수 있다!
|
from google.colab import drive
drive.mount('/content/drive')
-----
Go to this URL in a browser: https://acounts.google.com/......
Enter your autorization code:
(입력 창)
...
Mounted at /content/drive
|
cs |
일단 코랩에서 드라이브의 데이터를 쓰려면 자신의 드라이브를 코랩에서 쓸 수 있도록 마운트(Mount)해야 한다. 마운트는 어떤 장치를 컴퓨터 시스템에서 접근할 수 있도록 등록하는 일이라고 생각하면 된다.
위의 코드를 입력하면 어느 링크를 띄워준다.

링크를 클릭하면 아래와 같은 화면이 뜰 텐데, 구글 엑세스를 요청하는 것이므로 이 요청을 승인해야 코랩에서 현재 입력해야 하는 승인 코드를 받을 수 있다. 승인 코드가 뜨면 입력 창에 코드를 붙여넣기하고 확인을 눌러주면 마운트에 성공한다.
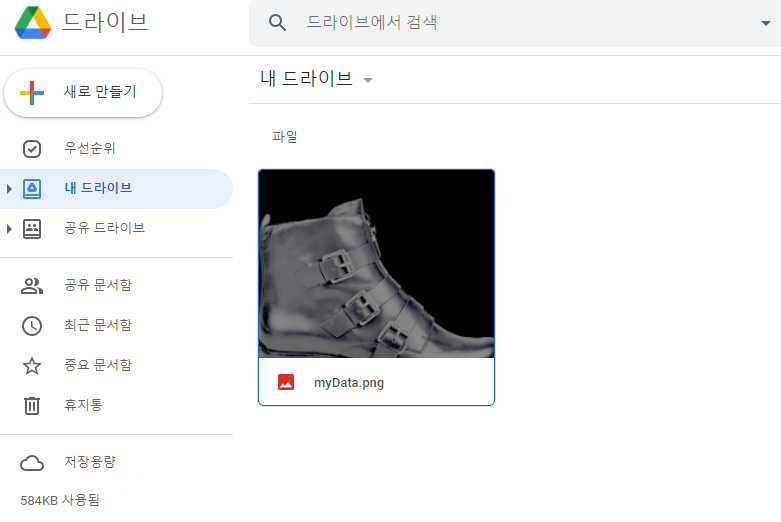
이제 구글 드라이브에 myData.png 를 저장해보자. 이는 13장에서 한 번 다뤘던 파일이므로 이미 컴퓨터의 어딘가에 저장되어 있을 것이다. 만약 다운받지 않았다면 이 책의 github 주소에서 다운받자!
|
!pwd #코랩이 현재 작업을 수행중인 위치
----
/content #content에서 작동 중.
|
cs |
현재 작업 중인 위치를 알고 싶으면 !pwd를 입력하면 된다. !는 코랩의 시스템 명령을 입력하는 기호이고, pwd는 'pring working directory'의 약어로, 현재 작업중인 위치를 출력하라는 뜻이다. 위의 결과를 살펴보면, 코랩은 /content에서 작동하며, 드라이브는 이 위치의 아래에 drive라는 이름으로 추가된다.
이제 myData.png가 코랩에서 확인되는지 살펴보자. 이를 위해서는 리눅스 시스템의 명령어를 몇 가지 써야 한다.
|
!ls ./drive/'My Drive' -la
---
total 585
-rw------- 1 root root 598385 May 27 06:12 myData.png
|
cs |
현재 위치는 /contents/이고, 내 드라이브의 내용을 살피고 싶으면 현재 디렉토리 아래에 마운트되어 있는 드라이브 디렉토리를 살피면 된다. 내 드라이브는 My Drive라는 이름으로 마운트되므로, 드라이브에 있는 파일을 확인하려면 위처럼 입력하면 된다. 이때 My Drive에는 따옴표를 꼭! 붙여 주어야 한다.
코랩에서 myData가 확인되는 것도 알았으니, 이제 코랩에서 이 이미지를 다뤄보자.

|
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
import cv2
img = mpimg.imread('./drive/My Drive/myData.png')
plt.imshow(img)
|
cs |
잘 불러와진다.
그런데 이 이미지를 모델에 적용하려면 일단 사이즈를 28*28로 줄여야 한다. 게다가 이것은 단일 채널 이미지가 아니라 RGB, 그리고 불투명도까지 포함된 4채널 이미지일 수도 있어서 회색조로 바꾸는 작업도 거쳐야 한다. 이는 13장에서 자세히 설명했으므로 더 설명하지는 않겠다.
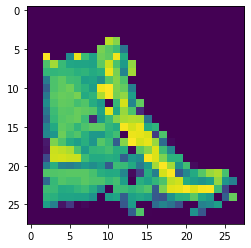
|
img = cv2.imread('./drive/My Drive/myData.png', cv2.IMREAD_GRAYSCALE)
img = cv2.resize(img, (28, 28))
plt.imshow(img)
|
cs |
cv2는 단색 채널을 가진 이미지를 가시화 할 때 회색조가 아닌 색상 맵을 적용하기 때문에 위처럼 회색조 필터를 씌워도 색상 맵이 적용되어 나온다. 이제 이것을 모델에 적용할 수 있게 되었다!
이미지를 모델에게 인식시켜 보자!
이제는 모델에 이미지를 인식시키는 것만이 남았다.
그런데 인식시켜보기 전에... 한 가지 걱정이 있다. 케라스에서 제공한 패션 MNIST 데이터에 있는 신발은 항상 신발의 코가 왼쪽을 향하도록 되어 있는데, 우리가 준비한 신발은 코가 오른쪽을 향하고 있다. 이런 이미지도 잘 인식할 수 있을까?
그래도 모르는 일이다. 일단 한 번 해 보자.
2차원 이미지를 3차원으로 가공하고, 모델에 적용시켜 본다.
|
input_data = img[np.newaxis, :, :]
#input_data.shape #(1, 28, 28) <- 3차원 배열로 바꿨다.
class_names = [ 'T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
yhat = np.argmax(model.predict(input_data))
print(class_names[yhat])
----
Bag #어라?
|
cs |
이럴 수가! 걱정한대로 잘못 인식했다.
그래도 괜찮다. 기계는 백지 상태에서 매번 신발의 코가 왼쪽으로 간 것만 보다가 오른쪽으로 간 것을 보게 된 것이니 모를 수밖에 없는 것이 어쩌면 당연하다. 그렇다면 코가 왼쪽으로 간 신발은 잘 구분할 수 있을까?

|
class_names = [ 'T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
yhat = np.argmax(model.predict(input_mirror))
print(class_names[yhat])
----
Ankle boot #이제 제대로 분류한다!
|
cs |
코가 왼쪽으로 가 있으니 이제서야 제대로 분류한다...

왜 컴퓨터가 방향이 다른 신발을 알아보지 못한 걸까?
학습이라는 것은 입력으로 주어진 데이터에 따라 한계를 가질 수밖에 없다. 케라스에서 제공한 신발이 모두 왼쪽으로 보고 있었기 때문에 오른쪽을 보고 있는 발목 부츠를 보면 신발이라고 인식하지 못하는 것이다. 이렇게 전체를 대표하지 못하고 특정한 특징이나 경향을 가진 데이터만 지나치게 학습에 많이 사용되는 것을 데이터 편향(Data Bias)이라고 한다.
데이터 편향은 학습된 모델이 올바르지 않은 판단을 내리게 만든다. 그래서 왼쪽을 보는 것은 발목 부츠로 인식하지만 오른쪽을 보는 것은 가방이라고 판단한 것이다. 이러한 문제를 해결하기 위해서는 편향되지 않은 다양한 데이터를 확보해야 한다. 하지만 많은 데이터를 구하는 데에는 한계가 있을 수 있기 때문에 원래 있던 데이터를 약간 변형하는 것도 좋은 방법이다. 이런 방법을 데이터 증강(Data Augmentation)이라고 한다.
인공지능: 딥러닝이 무엇일까?
요즘은 인공지능(Artificial Inteligence)이라는 용어가 자주 사람들의 입에 오르내린다. 이는 오래 전에 등장한 용어이지만, 사용하는 사람에 따라 그 뜻이 조금씩 다르다. 이 오래된 용어가 뜨기 시작한 것은 딥러닝(Deep Learning)의 성공 덕이 크다. 그래서 현재는 인공지능을 적용한다고 하면 거의 딥러닝을 적용한다는 말처럼 쓰인다.
딥러닝은 인공 신경망을 이용한 기계학습의 일종으로, 이름에서 알 수 있듯이 인공 신경망을 깊이 구축하는 것이다. 우리가 연습해본 신경망은 입력을 그대로 대응시켜 1차원 배열을 만드는 층이 입력층을 만들고, 첫 번째 Dense 네트워크가 중간 은닉층(Hidden Layer)으로 연결된다. 그리고 이 은닉층의 신호가 최종적으로 물체를 분류하는 출력층에 연결되도록 다시 Dense 네트워크를 적용하였다.
이렇게 층을 쌓다보면 은닉층이 여러 개인 신경망을 얻을 수 있고, 이것을 심층 신경망(Deep Neural Network)이라고 한다. 이러한 심층 신경망에서 학습을 진행하는 것이 딥러닝의 기본적인 개념이다.
|
model2 = keras.Sequential([
keras.layers.Flatten(input_shape = (28, 28)),
keras.layers.Dense(128, activation = 'relu'),
keras.layers.Dense(64, activation = 'relu'),
keras.layers.Dense(32, activation = 'relu'),
keras.layers.Dense(10, activation = 'softmax')
])
model2.compile(optimizer = 'adam',
loss = 'sparse_categorical_crossentropy',
metrics = ['accuracy'])
model2.fit(train_images, train_labels, epochs = 5)
----
Epoch 1/5
1875/1875 [==============================] - 6s 3ms/step - loss: 1.5992 - accuracy: 0.7602
Epoch 2/5
1875/1875 [==============================] - 5s 3ms/step - loss: 0.5272 - accuracy: 0.8186
Epoch 3/5
1875/1875 [==============================] - 5s 3ms/step - loss: 0.4818 - accuracy: 0.8309
Epoch 4/5
1875/1875 [==============================] - 5s 3ms/step - loss: 0.4391 - accuracy: 0.8433
Epoch 5/5
1875/1875 [==============================] - 5s 3ms/step - loss: 0.4173 - accuracy: 0.8518
<tensorflow.python.keras.callbacks.History at 0x7fe8d9e37550>
|
cs |
심층 신경망을 만드는 건 그렇게 어렵지 않다. 앞에서 했던 신경망에서 층을 더 쌓기만 하면 된다.
아까 했던 신경망보다 층이 2개 더 늘어났으므로 에폭 당 시간이 좀 더 걸릴 수 있지만, 에폭을 진행하는 동안 정확도가 85.18까지 올라간 것을 볼 수 있다. 은닉층이 하나인 것은 82% 정도였던 것을 생각하면 이 모델이 분류를 더 잘 하는 편이다.
이렇게 층을 쌓고 나서 얼마나 좋아졌는지 눈으로 확인하려면 사이킷런의 혼동행렬을 활용한다.


|
pred1 = model.predict(test_images) #층 1개 에폭 5
pred2 = model2.predict(test_images) #층 3개 에폭 5
y_hat1 = np.argmax( pred1, axis = 1) #결과 예측
y_hat2 = np.argmax( pred2, axis = 1) #결과 예측
from sklearn.metrics import confusion_matrix
conf_mat1 = confusion_matrix(test_labels, y_hat1)
conf_mat2 = confusion_matrix(test_labels, y_hat2)
plt.matshow(conf_mat1)
plt.matshow(conf_mat2)
|
cs |
층을 쌓아 학습을 시켰을 때에 눈에 띄는 변화는 클래스 6의 인식을 제대로 하는 경우가 늘었고, 전체적으로 잘못 분류한 경우의 푸른색이 옅어졌으므로 학습이 잘 된 것을 확인할 수 있다.
하지만 층이 많다고 해서 꼭 좋은 결과를 낳지는 않는다. 오히려 문제가 생긴다면 생긴다.
대표적인 문제는 모델이 복잡해서 계산 시간이 많이 소요된다는 점이다. 그리고 더 중요한 문제는 단순한 구조로 층만 깊이 쌓을 경우 출력 부분의 잘못에 근거한 학습의 내용이 입력에 가까운 네트워크 층까지 전파가 잘 되지 않는다는 것이다. 따라서 층이 깊어질수록 입력에 따라 다른 동작을 내도록 조정하기 어려워지는 것이다.
이러한 이유로 심층 구조는 학습이 이루어진다 해도 과적합이 되는 특성을 가진다.
심층 네트워크의 이러한 문제 때문에 신경망의 층을 깊이 쌓아 복잡한 문제를 해결하려던 노력이 몇 번 실패로 돌아갔고, 서서히 신경망 자체가 인공지능 분야에서 잊혀져가는 이유가 되기도 했다.
하지만 제프리 힌튼, 요수아 벤지오, 얀 르쿤 등이 합성곱 신경망(Convolutional Neural Network) 모델을 만들어내서 심층 신경망을 효과적으로 학습시킬 수 있는 돌파구를 찾았고, 그 이후 딥러닝 분야가 폭발적으로 발전하면서 이 세 사람은 인공지능 혹은 딥러닝의 대부로 불리며 컴퓨터 과학자에게 최고 영예인 튜링 상을 수상하게 된다.
텐서플로우를 이용하면 이러한 연구를 바탕으로 제안된 다양한 모델을 쉽게 구현하거나 가져다 쓸 수 있다. 이러한 모델이 어떻게 동작하고, 왜 좋은 결과를 내는지 깊이 이해하는 것은 이 분야 이론에 대한 체계적이고 전문적인 학습이 필요하다.
학습된 모델은 나중에도 쓸 수 있다!
지금까지 모델을 학습시키고 사용해보았다. 이렇게 학습된 모델을 한 번 쓰고 나중에 다시 만들어서 쓰려면 상당히 비효율적이다. 따라서 학습을 마친 모델을 저장해 두었다가 다음에 불러서 다시 사용하는 방법이 필요하다.
|
model2.save('./drive/My Drive/myFirstModel.h5') #My Drive에 저장
!ls ./drive/'My Drive' -la
----
total 1927
-rw------- 1 root root 598385 May 27 06:12 myData.png
-rw------- 1 root root 1373712 Jun 20 12:07 myFirstModel.h5 #저장됨!
|
cs |

방법은 간단하다! save()함수를 사용하면 된다. 구글 드라이브에 저장하고 드라이브 속 항목을 출력했더니 잘 저장되어 있는 것을 볼 수 있다.
그럼 이 모델을 다시 읽어오는 것도 해 보자.
|
model_imported = keras.models.load_model('./drive/My Drive/myFirstModel.h5')
model_imported.summary() #모델의 요약 정보
----
Model: "sequential_4"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_4 (Flatten) (None, 784) 0
_________________________________________________________________
dense_10 (Dense) (None, 128) 100480
_________________________________________________________________
dense_11 (Dense) (None, 64) 8256
_________________________________________________________________
dense_12 (Dense) (None, 32) 2080
_________________________________________________________________
dense_13 (Dense) (None, 10) 330
=================================================================
Total params: 111,146
Trainable params: 111,146
Non-trainable params: 0
_________________________________________________________________
|
cs |
이렇게 층의 개수가 잘 보이는 것을 보면... 불러오기도 제대로 된 것 같다!

|
import cv2
img = cv2.imread('./drive/My Drive/bag_cartoon.png', cv2.IMREAD_GRAYSCALE)
img = cv2.resize(img, (28, 28))
input_data = img[np.newaxis, :, :]
yhat = np.argmax( model_imported.predict(input_data))
print(class_names[yhat])
plt.imshow(img)
----
Bag #bag_cartoon.png 를 Bag이라고 인식한다.
|
cs |
불러온 모델을 가지고 다른 이미지로도 분류 작업을 진행할 수 있다.
마무리
이번 시간에는 텐서플로우와 딥러닝에 대해 알아보았다. 지금까지 정말 수고 많았다.
마지막으로! 심화문제 15.1을 풀어보고 마치도록 하자.
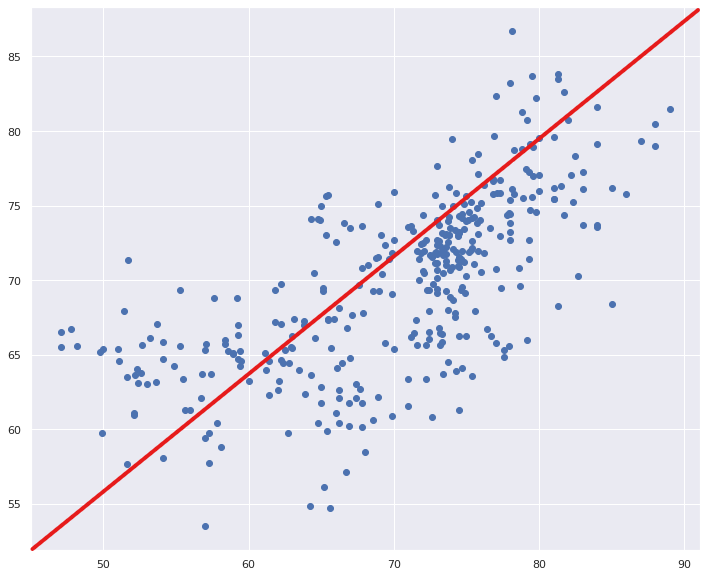
15.1 : 아래의 절차를 따라 수행한 뒤 x_test 데이터를 입력으로 받아 기대수명을 예측하고, 예측값을 목표값 y_test와 비교하여 일치하는지를 산포도 그래프로 확인하라.
|
import cv2import pandas as pd
#기대수명 csv를 읽어온다. (경로는 알아서!)
life = pd.read_csv('./drive/My Drive/life_expectancy.csv')
#원하는 열만 추출하고 결손값은 삭제한다.
life = life[['Life expectancy', 'Alcohol', 'Percentage expenditure', 'Measles',
'Polio', 'BMI', 'GDP', 'Thinness 1-19 years']]
life.dropna(inplace = True) #원본 데이터에서 삭제
#데이터를 학습용과 테스트용으로 분리.
from sklearn.model_selection import train_test_split
X = life[['Alcohol', 'Percentage expenditure', 'Measles',
'Polio', 'BMI', 'GDP', 'Thinness 1-19 years']]
y = life[['Life expectancy']]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)
#요소 값의 범위를 StandardScaler로 평균 0, 표준편차 1로 맞춘다.
from sklearn import preprocessing
scaler = preprocessing.StandardScaler().fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
#회귀 모델 만들기
import tensorflow as tf
from tensorflow import keras
model = keras.Sequential([
keras.layers.Dense(8, activation='relu'),
keras.layers.Dense(8, activation='relu'),
keras.layers.Dense(1, activation='relu')
])
#오차 구하기
model.compile(optimizer='adam',
loss = 'mse', #평균제곱오차
metrics = ['mse'])
#모델 학습
model.fit(X_train, y_train, epochs = 50)
|
cs |

'따라하며 배우는 파이썬과 데이터 과학 > PART 2. 데이터 과학과 인공지능' 카테고리의 다른 글
| Chapter 14. 기계학습으로 똑똑한 컴퓨터를 만들자 (0) | 2021.06.19 |
|---|---|
| Chapter 13. 시각 정보를 다루어보자 (0) | 2021.06.18 |
| Chapter 12. 판다스로 데이터를 분석해보자 (0) | 2021.06.17 |
| Chapter 11. 차트를 멋지게 그려보자 (0) | 2021.06.15 |
| Chapter 10. 넘파이로 수치 데이터를 처리해보자 (1) | 2021.06.15 |