
이번 시간의 목차
1. 키-값으로 이루어진 딕셔너리
2. 딕셔너리를 메소드로 다뤄 보자!
3. 이름이 없는 함수, 람다 함수
4. 순서가 중요하지 않다면 집합을 써 보자!
5. 집합 속 데이터를 상세하게 다뤄 보자!
6. 집합으로 연산을 해 보자!
7. 파일을 열어 자료를 읽고 저장하자!
8. 프로그래밍적 사고란?
9. 마무리
자, 가자! 파이썬의 세계로!
키-값으로 이루어진 딕셔너리
앞장에서 데이터를 하나로 묶어 한꺼번에 저장하는 방법 중 하나로 리스트를 다뤄보았다. 이번 장에서는 딕셔너리(Dictionary)에 대해 다루어 보자.
딕셔너리는 리스트와 다르게 값(Value)과 관련된 키(Key)가 있다는 것이 큰 특징이다. 예를 들자면 영단어 사전에서 단어와 그에 대응하는 뜻이 있을 때 단어가 키, 뜻이 값이 되는 것이다. 이렇게 파이썬의 딕셔너리는 서로 관련되어 있는 키와 값이 함께 저장되는데, 이것을 키-값 쌍(Key-Value Pair)라고 한다. 예시로 전화번호부를 만들어 보자.
|
>>> phone_book = {} #딕셔너리는 중괄호로 만든다.
>>> phone_book['홍길동'] = '010-1234-5678' #키-값 쌍을 추가하려면 왼쪽처럼 입력한다.
>>> phone_book['강감찬'] = '010-1234-5679'
>>> phone_book['이순신'] = '010-1287-8945'
>>> print(phone_book)
{'홍길동': '010-1234-5678', '강감찬': '010-1234-5679', '이순신': '010-1287-8945'}
|
cs |
딕셔너리를 출력하면 딕셔너리 속 항목(Item)이 쉼표로 구분되어 출력된다. 항목은 항상 키 : 값 형태로 출력된다. 딕셔너리의 항목에는 무슨 유형의 값이든 저장할 수 있다. 정수, 문자열, 다른 리스트, 다른 딕셔너리 등등... 다양한 정보를 담을 수 있다.
|
>>> phone_book['홍길동']
'010-1234-5678'
|
cs |
딕셔너리에서 가장 중요한 연산이라고 한다면 키를 가지고 연관된 값을 찾는 것이다. 키를 이용해 값을 찾으려면 위와 같은 코드를 사용하면 된다. 리스트에서 인덱스를 부르는 것과 비슷하게 생각하면 된다.
딕셔너리를 메소드로 다뤄 보자!
딕셔너리도 하나의 클래스인 만큼 메소드를 가지고 있다.
|
>>> phone_book.keys() #phone_book의 키를 전부 가져온다.
dict_keys(['홍길동', '강감찬', '이순신'])
>>> phone_book.values()#phone_book의 값을 전부 가져온다.
dict_values(['010-1234-5678', '010-1234-5679', '010-1287-8945'])
>>> phone_book.items() #phone_book의 항목을 (키, 값)의 튜플형태로 가져온다.
dict_items([('홍길동', '010-1234-5678'), ('강감찬', '010-1234-5679'), ('이순신', '010-1287-8945')])
#phone_book 속 항목을 items() 메소드로 하나씩 출력하기
>>> for name, phone_num in phone_book.items() :
print(name, ':', phone_num)
홍길동 : 010-1234-5678
강감찬 : 010-1234-5679
이순신 : 010-1287-8945
#phone_book 속 항목을 인덱스로 하나씩 출력하기
>>> for key in phone_book.keys() :
print(key, ':', phone_book[key])
홍길동 : 010-1234-5678
강감찬 : 010-1234-5679
이순신 : 010-1287-8945
|
cs |
key()메소드는 딕셔너리의 모든 키를 출력하고, values()는 모든 값을, item()는 딕셔너리 내부의 모든 값을 출력한다. 이때 items()메소드는 튜플 형태로 값을 반환하기 때문에 반복문으로 깔끔하게 출력할 수 있다.
딕셔너리 속에서 항목들은 자동으로 정렬되지 않기 때문에 sorted() 함수를 통해 정렬할 수 있다. 하지만 sorted() 함수가 반환하는 값은 키 값들의 리스트이기 때문에 모든 키-값 쌍에 대해 정렬하려면 함수 속 키워드 인자를 사용할 필요가 있다.
|
>>> sorted(phone_book) #sorted()는 key만 정렬한다.
['강감찬', '이순신', '홍길동']
>>> sorted_phone_book = sorted(phone_book.items(), key = lambda x: x[0]) #람다 함수를 이용한 가공
>>> sorted_phone_book
[('강감찬', '010-1234-5679'), ('이순신', '010-1287-8945'), ('홍길동', '010-1234-5678')]
|
cs |
위의 예시에서는 람다 함수를 사용해 가공했다. 람다 표현식은 바로 이 다음에 설명할 건데, 간단히 말해두자면 함수의 이름이 없는 1회용 함수로, 위의 key = lambda x : x[0]은 x를 인자로 받아 x의 첫 항목인 x[0]을 반환하는 기능을 한다.
딕셔너리의 항목을 삭제하려면 아래의 두 가지 방법을 사용할 수 있다.
|
>>> del phone_book['홍길동'] #키와 키에 대한 값을 모두 삭제한다.
>>> print(phone_book)
{'강감찬': '010-1234-5679', '이순신': '010-1287-8945'}
>>> phone_book.clear() #모든 항목을 삭제한다.
>>> print(phone_book)
{}
|
cs |
아래는 이 외에도 쓰이는 딕셔너리의 메소드이다.
| 메소드 | 하는 일 |
| keys() | 딕셔너리 내의 모든 키를 반환한다. |
| values() | 딕셔너리 내의 모든 값을 반환한다. |
| items() | 딕셔너리 내의 모든 항목을 [키]:[값]쌍으로 반환한다. |
| get(key) | 키에 대한 값을 반환한다. 키가 없으면 None을 반환한다. |
| pop(key) | 키에 대한 값을 반환하고, 그 항목을 삭제한다. 키가 없으면 KeyError 예외를 발생시킨다. |
| popitem() | 제일 마지막에 입력된 항목을 반환하고 그 항목을 삭제한다. |
| clear() | 딕셔너리 내의 모든 항목을 삭제한다. |
이름이 없는 함수, 람다 함수
조금 전에 sorted()함수를 사용하면서 람다 표현식(Lambda Expression)을 잠깐 사용해봤다. 람다 함수는 이름이 없는 함수로, 간단한 일회용 작업에 유용하게 쓰인다. 보통 함수는 만들어 두고 필요할 때마다 호출해서 쓰는데, 굳이 그렇게 만들지 않고 함수화된 기능만을 쓰고 싶을 때 람다 함수가 쓰인다.

일회용이라고 해서 재사용이 불가능한 것은 아니다. 표현식에 할당문을 사용해서 재사용할 수 있다. 다만 주의할 점이 있다. 표현식 안에서 새로운 변수를 선언할 수가 없다. 또, 표현식은 한 줄로 표현할 수 있어야 하기 때문에 복잡한 기능으로 들어가면 def로 함수를 새로 정의하는 것이 낫다.
이제 간단한 람다 함수 사용법을 알아보자.
|
>>> print('100과 200의 합:', (lambda x, y: x + y)(100, 200)) #100과 200이 람다 함수의 인자
100과 200의 합: 300
>>> t = (100, 200, 300)
>>> (lambda x: x[0])(t) #t를 인자로 받고 첫 항목인 t[0]을 반환
100
>>> (lambda x: x[2])(t) #t를 인자로 받고 세 번째 항목인 t[2]를 반환
300
>>> phone_book
{'강감찬': '010-1234-5679', '이순신': '010-1287-8945', '홍길동': '010-1234-5678'}
>>> sorted_phone_book1 = sorted(phone_book.items(), key = lambda x : x[0])
>>> sorted_phone_book1 #items()가 반환한 (키, 값) 중 첫 번째 항목인 키 순서대로 정렬
[('강감찬', '010-1234-5679'), ('이순신', '010-1287-8945'), ('홍길동', '010-1234-5678')]
>>> sorted_phone_book2 = sorted(phone_book.items(), key = lambda x : x[1])
>>> sorted_phone_book2 #items()가 반환한 (키, 값) 중 두 번째 항목인 값의 사전식 순서
[('홍길동', '010-1234-5678'), ('강감찬', '010-1234-5679'), ('이순신', '010-1287-8945')]
|
cs |
이렇게 다양한 식을 함수로 사용할 수 있다.
순서가 중요하지 않다면 집합을 써 보자!
리스트와 튜플을 다루면서 수학에서의 집합(Set)과 비슷하다는 느낌을 받은 적이 있나? 집합과 리스트, 튜플은 비슷하면서도, 항목의 중복 허용 여부와 순서의 존재 여부라는 차이가 있다.
파이썬에서 제공하는 집합은 순서가 없고, 동일한 값을 가지는 항목의 중복이 허용되지 않는다. 그리고 수학에서의 집합처럼 합집합, 교집합, 차집합, 대칭차집합 등의 다양한 연산을 수행할 수 있다. 순서가 없는 항목의 묶음을 원한다면 집합을 사용하는 것이 좋다.
|
numbers ={2, 5, 1, 2}
>>> numbers #중복된 요소는 하나만 남겨둔다.
{1, 2, 5}
>>> set([1, 23, 6, 124, 23, 9]) #리스트를 집합으로 만들 수도 있다.
{1, 6, 9, 23, 124}
>>> set("python") #문자열을 리스트로 만들 수도 있다.
{'n', 'h', 'p', 't', 'y', 'o'}
>>> num = set() #공백 집합
>>> num
set()
|
cs |
집합을 만들 때는 중괄호 {}를 사용한다. 앞서 말했듯 요소 간 중복을 허용하지 않기 때문에 중복된 요소가 있으면 자동으로 중복 요소를 삭제한다.
|
>>> numbers
{1, 2, 5}
>>> 2 in numbers #numbers 집합에 2가 있는지 검사
True
>>> for x in numbers: #집합의 요소를 하나씩 접근해서
print(x, end = ' ')
1 2 5
|
cs |
어떤 항목이 집합 안에 있는지를 검사하려면 리스트나 튜플과 마찬가지로 in 연산자를 사용할 수 있다.
그리고 집합에는 순서가 없으므로 인덱스로 항목에 접근할 수 없다. 대신 for 반복문을 이용하여 각 항목들에 접근할 수 있다.
|
>>> word = set('python')
>>> word
{'n', 'h', 'p', 't', 'y', 'o'} #알파벳 순서에 맞지 않는 출력
>>> for x in sorted(word) : #알파벳 순서로 정렬 후 하나씩 출력
print(x, end = ' ')
h n o p t y
|
cs |
집합을 만들고 나서 출력했을 때 입력한 순서대로 나오지 않더라도 너무 당황하지는 말자. 어차피 집합에서는 순서가 상관이 없기 때문에 입력한 순으로 나오든, 아무렇게 나오든 같은 데이터이다. 그래도 정렬 후 출력을 원한다면 sorted() 함수를 사용하고 출력하면 된다.
집합 속 데이터를 상세하게 다뤄 보자!
집합 속의 데이터를 좀 더 상세하게 다루는 방법에는 역시 두 가지가 있다. 바로 연산자, 메소드&함수를 사용하는 것이다.
먼저 연산자를 이용한 연산에 대해 알아보자.
|
>>> A = {1, 2, 3, 4}
>>> B = {1, 2, 3}
>>> A == B #A와 B가 같은지 검사한다.
False
>>> A < B #A가 B의 진부분 집합인지 검사한다.
False
>>> A >= B #B가 A의 부분 집합인지 검사한다.
True
|
cs |
보통 논리 연산과 비교 연산을 자주 이용한다. 비교 연산자 중 >, <과 >=, <=의 차이를 잘 알아두자. 등호가 붙으면 A와 B가 아예 같아서 서로의 부분집합이 되어도 True를 반환하지만, 등호가 붙지 않으면 아예 같을 때는 부분 집합 취급하지 않는, 즉 진부분 집합인지를 비교하기 때문에 False를 반환하게 된다.
두 번째로 메소드와 함수를 이용한 방법에 대해 알아보자.
|
>>> C = {0, 1}
>>> D = {0}
>>> all(A) #all() 는 모든 항목이 True인지를 검사한다.
True
>>> all(C) # 0은 False이므로 False를 반환한다.
False
>>> any(C) #any() 는 0이나 공백이 아닌 항목이 하나라도 있는지를 검사한다.
True
>>> any(D) #D = {0}이므로 False를 반환한다.
False
------------------------------
>>> E = {1, 5, 2, 3, 5, 6}
>>> len(E) #집합 E의 길이(중복은 제외한다.)
5
>>> max(E) #집합 E의 최댓값
6
>>> min(E) #집합 E의 최솟값
1
>>> sorted(E) #E를 정렬하여 리스트로 만든다. 중복은 제외.
[1, 2, 3, 5, 6]
>>> sum(E) #E 속 원소의 합을 구한다.
17
|
cs |
집합도 리스트와 마찬가지로 len(), max(), min(), sorted(), sum() 등의 메소드를 사용할 수 있다. 이때 주의해야 할 점은 중복된 데이터가 삭제되기 때문에 len(E)를 하면 E = {1, 5, 2, 3, 5, 6} 에서 눈에 보이는 것처럼 6을 반환하는 것이 아니라 중복이 삭제된 후 5를 반환하게 된다.
집합으로 연산을 해 보자!
파이썬의 집합은 수학에서 할 수 있는 집합 연산을 그대로 수행할 수 있다.
총 네 가지 연산을 할 수 있고, 보통 집합 연산 방법으로는 연산자와 메소드 두 가지가 있다. 연산 별로 하나씩 살펴보자.
1. 합집합 ( | , union)

|
>>> A = {1, 2, 3}
>>> B = {3, 4, 5}
>>> A | B #합집합 연산
{1, 2, 3, 4, 5}
>>> A.union(B) #합집합 메소드
{1, 2, 3, 4, 5}
|
cs |
2. 교집합 ( & , intersection)
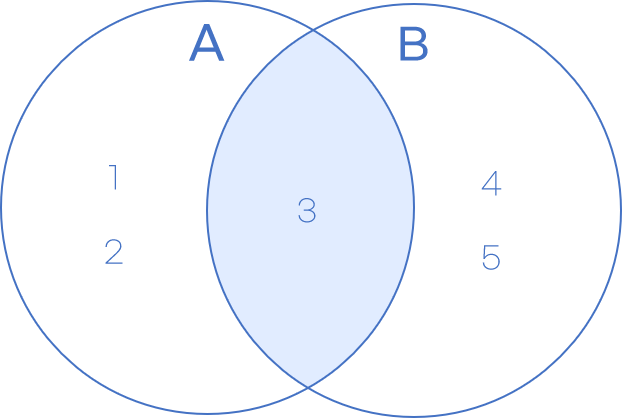
|
>>> A & B #교집합 연산
{3}
>>> A.intersection(B) #교집합 메소드
{3}
|
cs |
3. 차집합 ( - , difference)

|
>>> A - B #차집합 연산
{1, 2}
>>> A.difference(B) #차집합 메소드
{1, 2}
|
cs |
4. 대칭차집합( ^, symmetric_difference)

|
>>> A ^ B #대칭차집합 연산
{1, 2, 4, 5}
>>> A.symmetric_difference(B) #대칭차집합 메소드
{1, 2, 4, 5}
|
cs |
파일을 열어 자료를 읽고 저장하자!
컴퓨터에서 파일(File)이란 컴퓨터 저장 장치 내에 데이터를 저장하기 위해 사용하는 논리적인 단위를 말한다. 파일은 하드 디스크(Hard Disk)나 외장 디스크(External Disk) 같은 저장 장치에 저장한 후 필요할 때 다시 불러서 사용하거나 수정하는 것이 가능하다. 파일의 종류는 여러 가지이며, 일반적으로 파일이름.확장자명 형태로 저장된다. 이번에는 파이썬에서 .txt 파일을 다뤄보자.
|
>>> f = open('hello.txt', 'w') #파일을 쓰기 모드로 연다.
>>> f.write('Hello World!') #hello.txt 파일에 Hello World를 쓴다.
12
>>> f.close() #파일을 닫는다.
-------------------------------------------------------------------
>>> f = open('hello.txt', 'r') #파일을 읽기 모드로 연다.
>>> s = f.read() #hello.txt 파일을 읽는다.
>>> print(s) #파일의 내용을 출력한다.
Hello World!
>>> f.close() #파일을 닫는다.
|
cs |
위의 코드는 open()이라는 명령을 통해서 'hello.txt'파일을 열게 되는데, 뒤의 'w' 인자에 의해서 쓰기 모드로 열게 된다. 이렇게 만든 파일 객체 f는 write()명령을 통해서 'Hello World!'라는 문자열을 현재 디렉토리의 hello.txt라는 파일에 쓰고 모든 작업을 마친 후 close()를 통해 작업을 종료한다.

셸에서 바로 작업하면 Python39 파일 속에 hello.txt가 생긴 것을 볼 수 있다.
그리고 아래쪽 코드는 open()으로 함수를 열되, 뒤의 'r' 인자를 통해 읽기 모드로 불러온다. 이때 읽어들일 파일의 경로와 현재 파일의 경로가 일치해야 하니 주의하자. 성공적으로 파일 읽기가 완려되면 print(s)의 결과처럼 내용을 읽어들인 것을 볼 수 있다.
프로그래밍적 사고란?
보통 프로그래밍은 문제 해결 과정의 문제라고도 한다. 이런 문제 해결을 위해서는 프로그래밍적 사고 방식이 필요하다. 프로그래밍적 사고 방식이란 문제를 해결하는 단계적 과정을 고안해 보고 그 과정을 구현하는 것이다.
주어진 두 수의 최대공약수를 구하는 프로그램을 짜는 것으로 예시를 들어 보자.
1. 우선은 한 수에 대한 진약수를 구할 줄 알아야 한다.
어떤 한 수를 10이라 했을 때 10의 약수는 1, 2, 5, 10으로 총 4개가 있다. 이 중에서도 1과 자기 자신을 제외한 수, 즉 2와 5를 진약수라고 한다.
이 진약수는 어떤 수의 약수는 어떤 수를 약수로 나누었을 때 나누어 떨어진다는 특징을 이용하여 구할 수 있다.
|
>>> for i in range(2, 10) : #2에서부터 9까지 반복한다.
if 10 % i == 0 : #10을 각 수로 나눠서 나누어 떨어지면
print(i, end = ' ') #약수이므로 출력한다.
else :
continue #아니면 패스한다.
2 5
|
cs |
2. 두 수에 대한 진약수를 구해보자.
한 수에 대한 진약수를 구해봤으니, 이제 두 수에 대한 진약수를 각각 구해보자. 각각 구한 약수 중에서 공통된 값을 골라내면 공약수를 구할 수 있을 것이다. 그리고 공약수 중에서 최댓값을 찾아내면 그게 곧 최대공약수가 될 것이다.
|
>>> def get_divisors(num) : #빠른 약수 찾기를 위해 약수 찾기 함수를 정의했다.
divisors = set() #빈 집합을 만들어서
for i in range(2, num) :
if num % i == 0 :
divisors.add(i) #약수이면 약수 집합에 넣는다.
return divisors #그리고 약수 모음 집합을 반환
>>> x, y = 48, 60 #48과 60의 진약수를 구해보자.
>>> print(x, '의 진약수 :', get_divisors(x), '\n', y, '의 진약수 :', get_divisors(y))
48 의 진약수 : {2, 3, 4, 6, 8, 12, 16, 24}
60 의 진약수 : {2, 3, 4, 5, 6, 10, 12, 15, 20, 30}
|
cs |
위처럼 48과 60의 약수가 잘 골라진 것을 볼 수 있다.
48의 진약수 집합과 60의 진약수 집합의 공통 부분을 찾으려면 방금 배운 집합의 교집합 연산자 &나 교집합 메소드 intersection() 을 사용하면 된다. 그 중에서 최댓값을 찾아오려면 max()를 사용하면 된다.
|
>>> divisors_48, divisors_60 = get_divisors(x), get_divisors(y) #48과 60 각각의 약수를 변수로 선언
>>> allround = divisors_48 & divisors_60 #교집합으로 공약수 집합을 만든다.
>>> print(x, y, '의 최대공약수 :', max(allround)) #교집합 집합 중 최댓값을 구한다.
48 60 의 최대공약수 : 12
|
cs |
이렇게 단계적으로 고민하고 답을 찾아나가는 것이 프로그래밍적 사고다.
마무리
이번 시간에는 딕셔너리와 람다 함수, 집합, 그리고 프로그래밍적 사고에 대해 알아보았다.
마지막으로 도전문제 8.2와 심화문제 8.3을 풀어보고 마치도록 하자. 접은글 속 해답코드는 참고만 하자.
도전문제
8.2 : LAB 8-1의 프로그램을 편의점의 재고를 관리하는 프로그램으로 업그레이드해보자. 즉 재고를 증가, 또는 감소시킬 수도 있도록 코드를 추가하여 보자. 재고 조회, 입고 출고와 같은 간단한 메뉴도 만들어보자.
|
#items = { '커피음료' : 7, '펜' : 3, '종이컵': 2,
'우유' : 1, '콜라' : 4, '책' : 5 }
메뉴를 선택하시오 1)재고조회 2)입고 3)출고 4)종료 :1
[재고조회] 물건의 이름을 입력하시오: 콜라
재고 : 4
메뉴를 선택하시오 1)재고조회 2)입고 3)출고 4)종료 :2
[입고] 물건의 이름과 수량을 입력하시오: 콜라 4
콜라 의 재고 : 8
메뉴를 선택하시오 1)재고조회 2)입고 3)출고 4)종료 :3
[출고] 물건의 이름과 수량을 입력하시오: 콜라 7
콜라 의 재고 : 1
메뉴를 선택하시오 1)재고조회 2)입고 3)출고 4)종료 :4
프로그램을 종료합니다.
|
cs |
|
while True : #무한 루프로 시작한다.
menu = int(input('메뉴를 선택하시오 1)재고조회 2)입고 3)출고 4)종료 :')) #작업을 묻는다.
if menu == 4 :
print('프로그램을 종료합니다.')
break #4번 종료 메뉴를 선택하면 루프를 빠져나온다.
elif menu == 1:
name = input('[재고조회] 물건의 이름을 입력하시오: ')
print('재고 :', items[name]) #items의 name으로 접근해서 value를 반환한다.
elif menu == 2:
name, num = input('[입고] 물건의 이름과 수량을 입력하시오: ').split(' ') #공백으로 글자와 수를 분리
items[name] = items[name] + int(num) #value에 입력된 재고를 더한다.
print(name, '의 재고 :', items[name])
elif menu == 3:
name, num = input('[출고] 물건의 이름과 수량을 입력하시오: ').split(' ')
if items[name] < int(num) : #value보다 큰 값을 빼기는 불가능하다.
print('재고가 부족합니다!')
else :
items[name] = items[name] - int(num) #value에 입력된 재고를 뺀다.
print(name, '의 재고 :', items[name])
|
cs |
심화문제
8.3: 학번, 이름, 전화번호의 3쌍의 요소를 가지는 student_tup라는 튜플이 다음과 같이 존재한다.
|
student_tup = (('211101', '최성훈', '010-1234-4500'), ('211102', '김은지', '010-2230-6540'),
('211103', '이세은', '010-3232-7788'))
|
cs |
1) 이 튜플을 수정하여 { 학번 : [이름, 전화번호] }의 쌍으로 이루어진 딕셔너리를 만들어서 출력하라.
|
학생의 정보 목록
{'211101' : ['최성훈', '010-1234-4500']}
{'211102' : ['김은지', '010-2230-6540']}
{'211103' : ['이세은', '010-3232-7788']}
|
cs |
|
student = {'211101' : ['최성훈', '010-1234-4500'], '211102' : ['김은지', '010-2230-6540'],
'211103' : ['이세은', '010-3232-7788'] }
print('학생들의 정보 목록')
for key in student.keys() :
print('{', end ='')
print("'{}' : {}".format(key, student[key]), end = '')
print('}', end = '\n')
|
cs |
2) 이 정보를 이용하여 학생의 학번을 입력으로 받아서 이름과 전화번호를 출력하는 학사 정보 프로그램을 작성하여라.
|
학번을 입력하시오 : 211103
이름 : 이세은
연락처 : 010-3232-7788
|
cs |
|
student = {'211101' : ['최성훈', '010-1234-4500'], '211102' : ['김은지', '010-2230-6540'],
'211103' : ['이세은', '010-3232-7788'] }
num = input('학번을 입력하시오: ')
print('이름 :', student[num][0])
print('연락처 :', student[num][1])
|
cs |
3) student_tup의 마지막 항목으로 직전학기의 학점을 추가하여라. 세 학생의 학점은 각각 4.3, 3.9, 4.25이다. 이 정보를 바탕으로 다음과 같은 딕셔너리를 만들어서 학생 정보를 출력하여라.
|
학생의 정보 목록
{'211101' : ['최성훈', '010-1234-4500', 4.3]}
{'211102' : ['김은지', '010-2230-6540', 3.9]}
{'211103' : ['이세은', '010-3232-7788', 4.25]}
|
cs |
|
student = {'211101' : ['최성훈', '010-1234-4500', 4.3], '211102' : ['김은지', '010-2230-6540', 3.9],
'211103' : ['이세은', '010-3232-7788', 4.25] }
print('학생의 정보 목록')
for key in student.keys() :
print('{', end ='')
print("'{}' : {}".format(key, student[key]), end = '')
print('}', end = '\n')
|
cs |
4) 문제 3)의 정보를 이용하여 for 반복문과 인덱싱을 통해서 세 학생의 학점의 평균값을 다음과 같이 출력하여라.
|
전체 학생의 학점 평균 : 4.0
|
cs |
'따라하며 배우는 파이썬과 데이터 과학 > PART 1. 파이썬 기초체력 다지기' 카테고리의 다른 글
| Chapter 07. 데이터를 리스트와 튜플로 묶어보자 (1) | 2021.06.13 |
|---|---|
| Chapter 06. 함수로 일처리를 짜임새있게 하자 (0) | 2021.06.11 |
| Chapter 05. 여러 번 반복하는 일을 하자 (0) | 2021.05.30 |
| Chapter 04. 조건을 따져 실행해보자 (2) | 2021.05.29 |
| Chapter 03. 연산자로 계산을 해 보자 (2) | 2021.05.27 |